Datatonic Open Sources ‘Data Orchestration Platform’

7th April 2021
Data Orchestration is a relatively new concept referring to a set of technologies that takes data from multiple sources, combines and organises it, and makes it readily available for analytics. However, getting data in the right shape and right place has become extremely complex, due to the exponential growth in volume, variety and velocity of data.
39% of even highly data-driven companies have 50+ data silos.
70% of a company’s data goes unused for analytics purposes.*
On top of these data challenges, businesses often lack the internal tools to manage their data needs, leading to a lack of data governance, time-consuming and resource-intensive processes, and poor data quality to make effective business decisions.
At Datatonic, we believe this should be easier. Data orchestration should be simpler and more accessible to a wider group of people, which is why we’ve open-sourced our ‘Data Orchestration Platform’ [DOP] on GitHub. And, in the spirit of open source, we’ve asked our team members to contribute to this announcement post explaining the vision and impact of DOP.
Firstly, what is Data Orchestration?
To define Data Orchestration, our Machine Learning Engineer, Elia Secchi, compares it to an actual orchestra.
“When talking about IT systems and Cloud Architectures, the word Orchestration refers to the automated configuration, coordination, and management of computer systems and software. This originates from the classical music definition of Orchestration, defined as the study or practice of writing music for an orchestra.
I always found really accurate the usage of this word when talking about computing systems: if we think of our system as an orchestra, each one being a different instrument, the orchestrator would be for sure the conductor of the orchestra, fitting together all the different instruments in order to play the song. Just as the conductor is a crucial part of the orchestra, the orchestrator plays a central role in any Cloud Data Architecture.”
Secondly, why has Orchestration become so difficult?
Our Principal Business Intelligence Developer, Ash Sultan, leans in the common pain points that data engineers and developers often face.
“Transformations in many organisations are often done in silos. It’s typically a combination of manually put together scripts running on people’s laptops or as part of scheduled jobs in BI tools such as Looker or Tableau with very limited or no version control, not following best practices and with large amounts of duplication. This often means data quality is poor and it has a direct impact on an organisation’s ability in making the right business decision.”
What is the Data Orchestration Platform [DOP], and why was it created?
The “composer” and the driving force behind DOP, Richard He, explains the platform’s vision.
“DOP is designed to simplify the orchestration effort across many connected components using a configuration file without the need to write any code. We have a vision to make orchestration easier to manage and more accessible to a wider group of people.
We’re able to achieve this through the following design concepts:
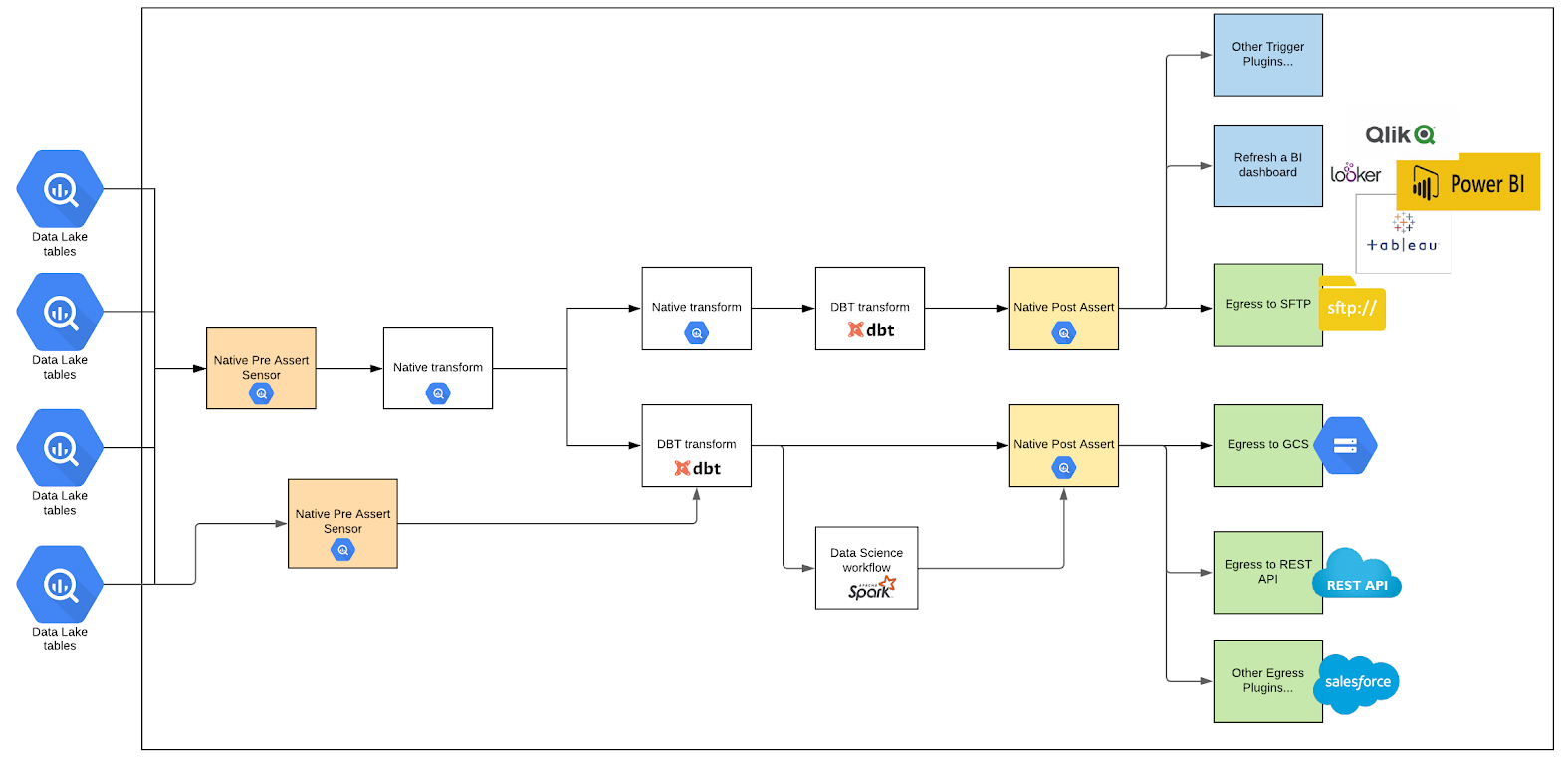
- Directed Acyclic Graphs (DAGs) without code – YAML + SQL
- Native capabilities (SQL) – Materialisation, Assertion and Invocation
- Extensible via plugins – dbt job, Spark job, Egress job, Triggers, etc
- GUI support – Built on top of Apache Airflow, interactive GUI
- Easy to set up and deploy – fully automated dev environment and easy to deploy.
- Open source – Open sourced under MIT license
Naturally, as a Data + AI specialist partner for Google Cloud Platform, the DOP is heavily optimised to run with GCP services. Focusing on one cloud provider has allowed us to optimise the end-user experience through greater automation.”
How is DOP different to another open-source tool, dbt?
See below a break down how DOP works hand-in-hand with data transformation tool, dbt.
“As many data engineers know, deploying dbt jobs isn’t all that simple too. You’ll need to consider the following:
- How many service accounts are needed, what permissions, and where to store credentials?
- How to break down complex dbt jobs (i.e. dbt run + dbt test, modules, tags etc)?
- How to test things end-to-end locally and visualise what is happening?
- How to easily deploy the same flow to Cloud Composer?
- How about python dependency conflicts on Cloud Composer?
DOP makes the deployment of dbt jobs simpler and seamless, through the following features:
- No credentials or keys stored, only service account impersonation
- Transient python virtualenv locally with Docker Compose + Run in Containers on Cloud Composer
- Mirroring Cloud Composer pip dependency on Docker to ensure the best compatibility
- Orchestration managed using an Airflow DAG generated from a simple YAML file
- Service Project Oriented Architecture (works well with companies that already have existing dbt jobs & Composer Cluster)
- Predefined Terraform script templates for dev, test and prod to managing permissions following best practices
So, what do our clients have to say about it?
Jorge Ramon, Data Engineering Lead at Epidemic Sound, a global music technology company, explains DOP as the “missing piece”!
“Airflow is great. But having to write Python to schedule and orchestrate jobs entirely written in SQL simply defeats the purpose. At the same time, dbt is great, but having to set up a separate orchestration for your dbt jobs is far from ideal. Datatonic’s Data Orchestration Platform is just the missing piece that seamlessly allows you to orchestrate dbt jobs in your existing Airflow instance with no Python required.”
Try it out yourself!
You can find the DOP project on Team Datatonic’s Github to apply to your business – github.com/teamdatatonic/dop
For more information on our cloud data engineering services, see our solution overview here.
__
* Sources: 451 Research 2020 Survey, ESG 2020 Technical Review.
