MLOps Tools Part 5: BigQuery + Memorystore vs. FEAST for Feature Store

Welcome to the last post of our blog series on MLOps on Google Cloud!
In previous weeks, we have released blogs covering Data Transformation, Orchestration, Serving, and Monitoring. In this final part of the series, we will look at implementing a feature store on Google Cloud in two ways: using a combination of BigQuery and Memorystore; and using the open-source tool FEAST.
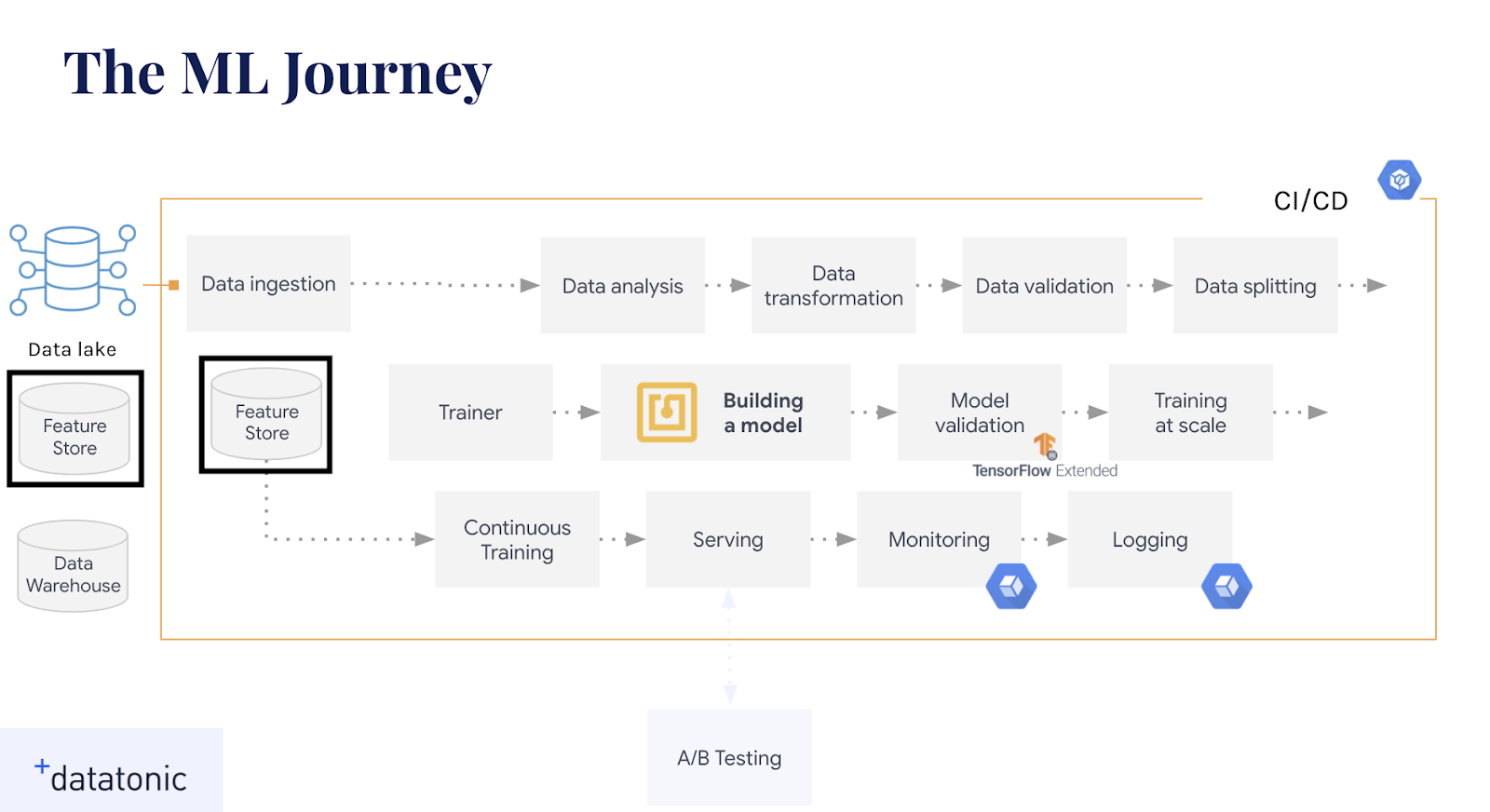
What is a feature store?
Feature stores are often an overlooked part of the MLOps journey, and yet their role can be pivotal in operationalising machine learning. A feature store can be best described as the interface between the raw data and the model, or between a data engineer and a data scientist. It allows data engineers to ingest raw data into a central repository ready for data scientists to experiment on, and allows data scientists to consistently create and retrieve features for various model use cases. However, a good feature store is much more than just storing feature data: serving features consistently, monitoring feature performance, storing feature metadata, and even managing the data transformation and ingestion processes are also of key importance.

In this diagram we can see the core components of a feature store split into multiple sections. Whilst storage is normally the main focus in mind, there is also transformation, serving, operational monitoring, and a registry to think about.
In addition, the storage capacity of a feature store is normally split into an offline store and an online store. Offline stores contain the archive of feature data, which can be used for model training or in batch predictions. The online store serves the latest known value of the features with minimum latency (see our third post titled “Cloud Functions vs. Cloud Run for Model Serving” for more on online serving on Google Cloud Platform).
Feature stores are still a novel idea to a lot of teams, with implementations still in their infancy. We will now explore two different ways of implementing a feature store on Google Cloud Platform.
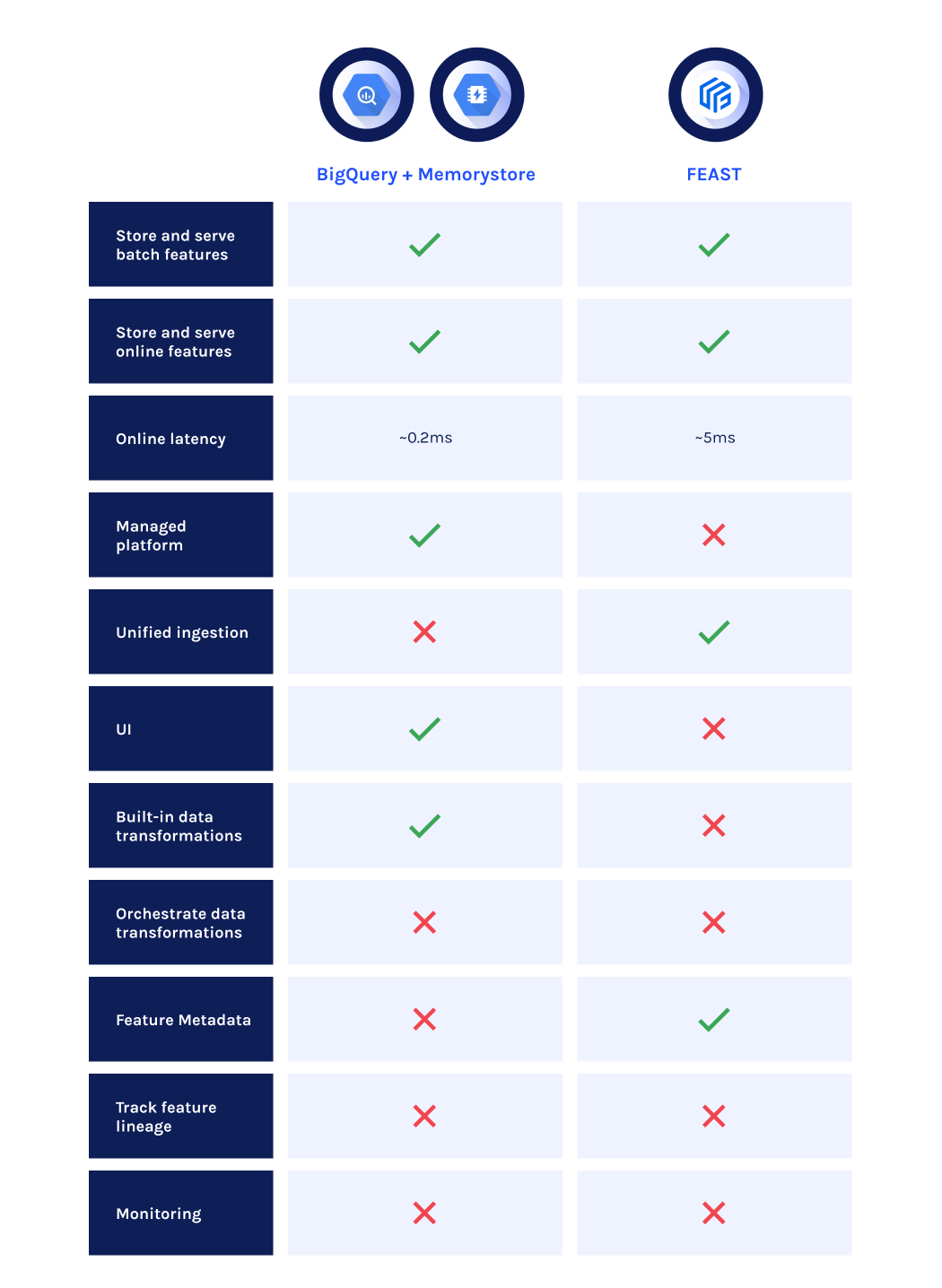
BigQuery + Memorystore
We previously introduced BigQuery in the first post called “TensorFlow Transform vs. BigQuery for Data Transformation”. Here it was viewed as a tool for data transformation, and we focused more on its compute capabilities. BigQuery also offers traditional RMDBS storage in the form of datasets and tables which can easily be queried with SQL, making it an ideal choice for the offline store component of a feature store.
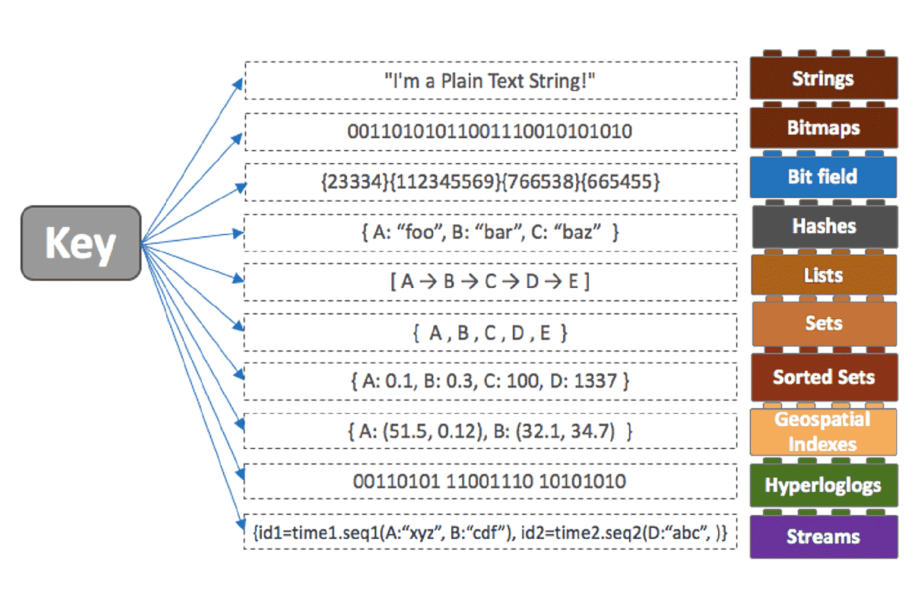
Meanwhile, Memorystore (see more here) is Google’s managed implementation of the open-source key:value database Redis, which offers in-memory caching of non-relational data. An in-memory database is a good choice for an online store, as it enables extremely low latency feature lookups. Redis also has the advantage of being able to store different types of values depending on the feature, optimising retrieval of items like Strings, Lists, and Hashes separately.
Combining both BigQuery and Memorystore thus gives us a managed offline and online store on Google Cloud Platform.
Reasons to use BigQuery + Memorystore
- Managed services : BigQuery and Memorystore are well established tools on Google Cloud Platform, meaning that they can integrate well with plenty of other services, and are backed by Google Cloud’s SLAs. As FEAST is an open-source offering it may not necessarily integrate with your GCP stack as well as BigQuery and Memorystore.
- Low latency online retrieval: For retrieving online features it’s hard to beat the speed of Memorystore, which can easily achieve sub-millisecond latency thanks to the underlying Redis database. Although it also uses Redis as an online store, FEAST can’t quite manage the sub-millisecond latency offered by Memorystore due to additional overheads in querying feature metadata and other checks. Of course you can implement these checks yourself, and that would add latency to Memorystore, but you have more control over the increase in latency.
- Manage both storage and data transformations: Using BigQuery allows you to harness its capabilities as a data transformation tool, using simple SQL code to define your features and store them. With FEAST the features already have to be created and stored elsewhere, before you can ingest them into the feature store.
FEAST
FEAST (see more here) is an open source feature store tool, which was developed by Google Cloud and GO-JEK and released in 2019. It combines both an offline and online store into one unified tool.
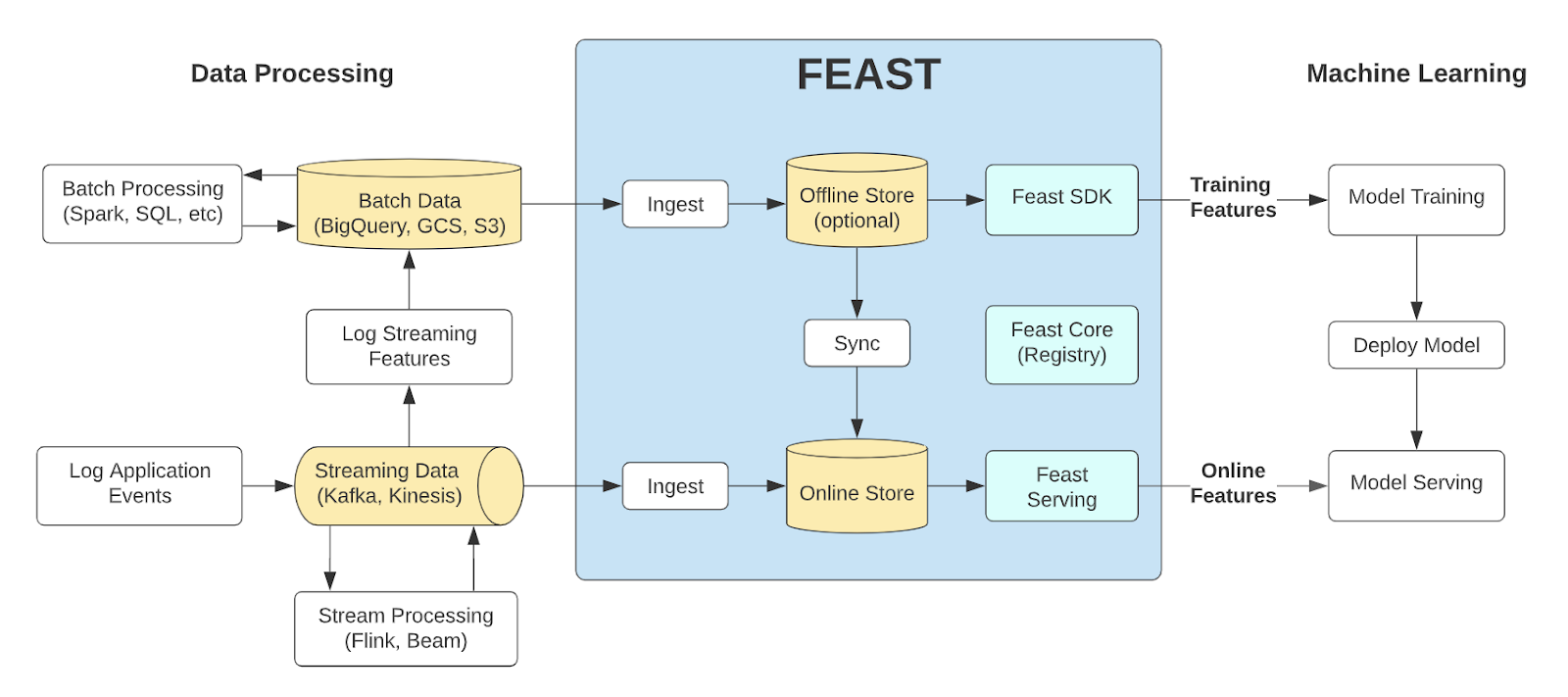
On top of offline and online storage, FEAST also offers a feature registry, allowing users to create, share and reuse features all through a centralised platform; as well as a dedicated python SDK for interacting with the store. FEAST stores features using the entity data model:
- First an entity is created, which is used as a primary key for matching features across feature tables;
- Then you declare your features, specifying their name and data type;
- Now you instantiate your feature tables using the entities you registered. These contain your features, and also specify the (batch or streaming) data source that they come from;
- Finally you register your entities and feature tables in the Feast Core registry, and submit jobs to ingest data.
Using this structure allows users to impose a strict hierarchy and organisation of features, making it clear which features are linked to which entities and where they come from.
Reasons to use FEAST
- Dedicated feature store: FEAST offers a one-tool-to-rule-them-all approach to the feature store. Using the same SDK, you can easily ingest features into either an offline store or online store, and keeping features up-to-date is also done within the tool itself. FEAST doesn’t just focus on storage capabilities either; it also offers a feature registry, as well as consistent serving of features. On the other hand, BigQuery and Memorystore need to be interacted with in different ways, and they have separate storage patterns and restrictions, meaning there will be more overhead in streamlining features between the two. In addition, using BigQuery and Memorystore only solves for the storage part of the feature store equation, and would require additional tools on top for more functionality.
- Strict organisation and feature hierarchy: FEAST provides a consistent organisation of your features in both the offline and online store, helping to avoid training-serving skew. It also offers point-in-time feature retrieval when exporting features for training, ensuring there is no feature leakage. Storing features in a registry allows users from across the organisation to keep track of the same features, as well as check feature metadata and data quality, and the entity data model ensures that features can be organised in a logical manner. As BigQuery is a relational database, it is possible to store features in a similar structure here, although it is not imposed as strongly as in FEAST. Moreover, Memorystore is strictly non-relational, so no storage structure can be imposed (outside of setting keys with different types of values).
- Managed data ingestion: FEAST provides connections to both batch and streaming data sources, meaning you can manage the feature ingestion from within the tool itself. It also provides automatic refreshing of data from a streaming source. With BigQuery/Memorystore, you would need an additional tool (like Cloud Dataflow or Cloud Dataproc) to manage any batch or streaming data ingestion pipelines.
Summary
Whilst BigQuery combined with Memorystore will cover your storage needs and provides the lowest online latency, a dedicated feature store also needs much more functionality.
We would recommend using BigQuery + Memorystore if you want a simple managed offering of an offline and online store backed by strict SLAs. With FEAST comes more organisation and streamlined tooling, but at the cost of deploying and managing the library yourself. However, both offerings still lack some desired functionality, especially with regards to orchestrating the data transformations before ingestion (See the second post on “Kubeflow Pipelines vs. Cloud Composer for Orchestration” for more on orchestration tools).
Google Cloud recently announced that it will be adding a managed feature store service to AI Platform, which will look to provide many of the additional options that a dedicated feature store requires. With word of other companies also producing managed feature store offerings, we expect plenty of development around this area of MLOps.
Check out our 2021 Guide to MLOps for information on getting started!


