Running dbt on Google Cloud’s Vertex AI Pipelines

If you’ve browsed around Google Cloud’s offerings, worked in the data transformation space or have a general interest in AI workflows, chances are you’ve heard of dbt or Vertex AI. But, how can you use them together in an efficient and cost-effective way to orchestrate Machine Learning workloads?
Before diving deeper into running dbt on Vertex AI pipelines, let’s take a quick look at each tool individually.
dbt
dbt is an analytics workload tool that allows you to manage a variety of complex in-warehouse SQL transformations. As part of the modern stack this is being used by Analytics Engineers to build data warehouses and data marts, but can be easily used for many types of data transformations such as pre-processing and feature engineering for data science workloads.
dbt leverages ELT as opposed to more traditional ETL type frameworks, a trend we’re starting to see more as the processing power and flexibility of Data Warehouses and Data Lakes continues to improve. Additionally, ELT tools often give the developer the opportunity to write transformative steps in SQL as opposed to somewhat less accessible procedural languages such as Python, Java and Scala.
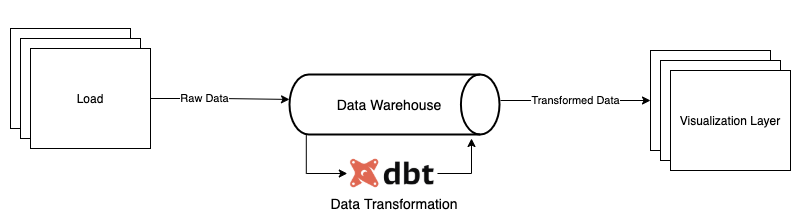
The question then becomes: How do we orchestrate our ELT workloads?
On Google Cloud, the obvious answer is Composer, using Airflow under the hood to schedule and run transformative steps. However, Composer’s heavy-duty 3 node minimum GKE cluster can make it a costly option for low frequency or transient data transformations. In addition to this, if dbt is used in conjunction with Machine Learning models and more Data Science focused workloads, often sitting in Vertex AI, orchestrating between Composer and Vertex AI can prove complex. Enter Vertex AI Pipelines, a new service introduced by Google Cloud to develop, orchestrate and run ML workloads on Google Cloud utilising the Kubeflow Pipelines SDK.
Vertex AI Pipelines
Vertex AI Pipelines breaks down transformative steps into pipeline steps, each run using a Docker Container all holding ephemeral data and is executed serverlessly. Aside from the standard benefits, such as the Kubeflow SDK, Python-based containers defined as functions, and the seemingly frictionless connection to other Vertex AI services the pipelines can prove to be rather cost-effective as you only pay for the time the processing occurs, plus resources consumed in by the run.
Integrating dbt and Vertex AI Pipelines
Integrating dbt into Vertex AI Pipelines allows for the pre-processing of data as well as feature engineering, whilst easily integrating into a machine learning pipeline, which benefits from model training and validation.

In reality, this pipeline could have multiple model training steps with multiple dependent data transformation steps preceding and proceeding.
All that’s left now is developing and running dbt pipeline steps.
dbt on Vertex AI Pipelines in 4 steps
Prerequisites – Local Runs
- A Google Cloud project with billing enabled and a service account to trigger the pipeline with the following permissions at a minimum:
- roles/aiplatform.user
- roles/iam.serviceAccountUser
- If your pipeline interacts with other services they’ll need to be added.
- The following Google Cloud API’s activated:
- artifactregistry.googleaps.com
- aiplatform.googleapis.com
- iam.googleapis.com
- Python 3.8
- pip with the following packages installed and ready to use:
- Docker Installed
- The gcloud CLI tool installed
- A GCS bucket to store Pipeline Artifacts
1. Write your Docker file
First things first, if we’re going to be running a containerised step for dbt we’ll need a container image. There are options here, either pull a docker image directly from Fishtown Analytics: https://hub.docker.com/r/fishtownanalytics/dbt, or find a custom image such as this one I’ve adapted below: https://github.com/davidgasquez/dbt-docker.
NOTE: Ensure you replace the COPY operation below with the path to your dbt project specifically.
FROM python:3.8.5
RUN apt-get update -y &&
apt-get install --no-install-recommends -y -q
git libpq-dev python-dev &&
apt-get clean &&
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
RUN pip install -U pip
RUN pip install dbt==0.19.0
ENV dbt_DIR /dbt
WORKDIR $dbt_DIR
#This will need to be replaced
COPY </PATH/TO/YOUR/dbt/PROJECT/> /dbt
RUN mkdir ~/.dbt
CMD ["bash"]
2. Pushing your image to the Artifact Registry
Next up we need to create our Artifact Registry Repository for dbt images and push our dbt image into that repository.
Google provides pretty good instructions on how to set up your repository and push to it using docker: https://cloud.google.com/vertex-ai/docs/training/create-custom-container.
3. Define your KFP Pipeline
Now that all the infrastructure is in place, it’s time to define our pipeline code. We’ll need two files to get started: a component spec writing in YAML file to define our dbt jobs (for more information on spec files please see the KFP documentation).
Below is a very simple yaml spec file that could be used to run dbt:
name: dbtRun
description:
Run the dbt job
implementation:
container:
image:<insert artifact registry image here i.e: “europe-west1-docker.pkg…@sha256:30461”>
command:
- dbt
- run
You’ll also need a python script to define our pipeline, ensuring we’re replacing the path to the component spec file above:
from google.cloud.aiplatform.pipeline_jobs import PipelineJob
from kfp import components, dsl
from kfp.v2 import compiler
# Loads the component file as a component
dbt_component = components.load_component_from_file('./component_spec.yml')
# Pipeline definition occurs here
@dsl.pipeline(name='my-first-dbt-pipeline')
def dbt_pipeline():
dbt = dbt_component()
# Compiles the pipeline defined in the previous function into a json file executable by Vertex AI Pipelines
def compile():
compiler.Compiler().compile(
pipeline_func=dbt_pipeline, package_path='pipeline.json', type_check=False
)
# Triggers the pipeline, caching is disabled as this causes successive dbt pipeline steps to be skipped
def trigger_pipeline():
pl = PipelineJob(
display_name="FirstPipeline",
enable_caching=False,
template_path="./pipeline.json",
pipeline_root="gs://test-artifacts-vertex-ka"
)
pl.run(sync=True)
if __name__ == '__main__':
compile()
trigger_pipeline()
4. Trigger your pipeline
This next step is simple! Run the python file either from a local machine or using an external Google Cloud service. If everything is configured correctly, you’ll have a running dbt pipeline:
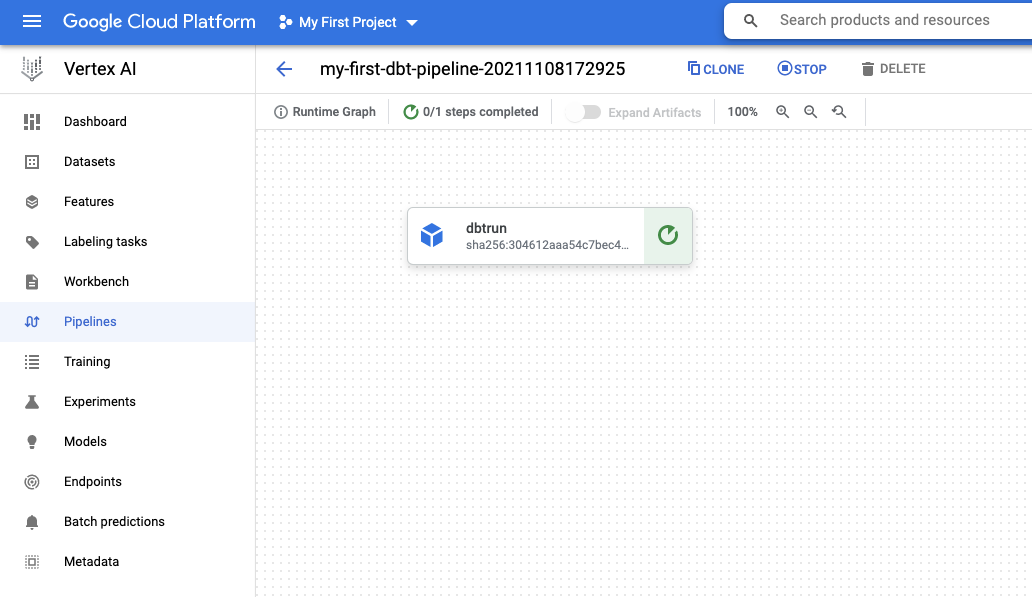
The above script will use the default compute service account by default <project-number>-compute@developer.gserviceaccount.com.
Optionally, the PipelineJob run method allows you to specify a custom service account at runtime. I’d recommend using this with a more least-privilege approach used to define the role list in a production setting.
Below, we have provided an example architecture on how to run Vertex AI Pipelines using dbt. This is just one way to do it.
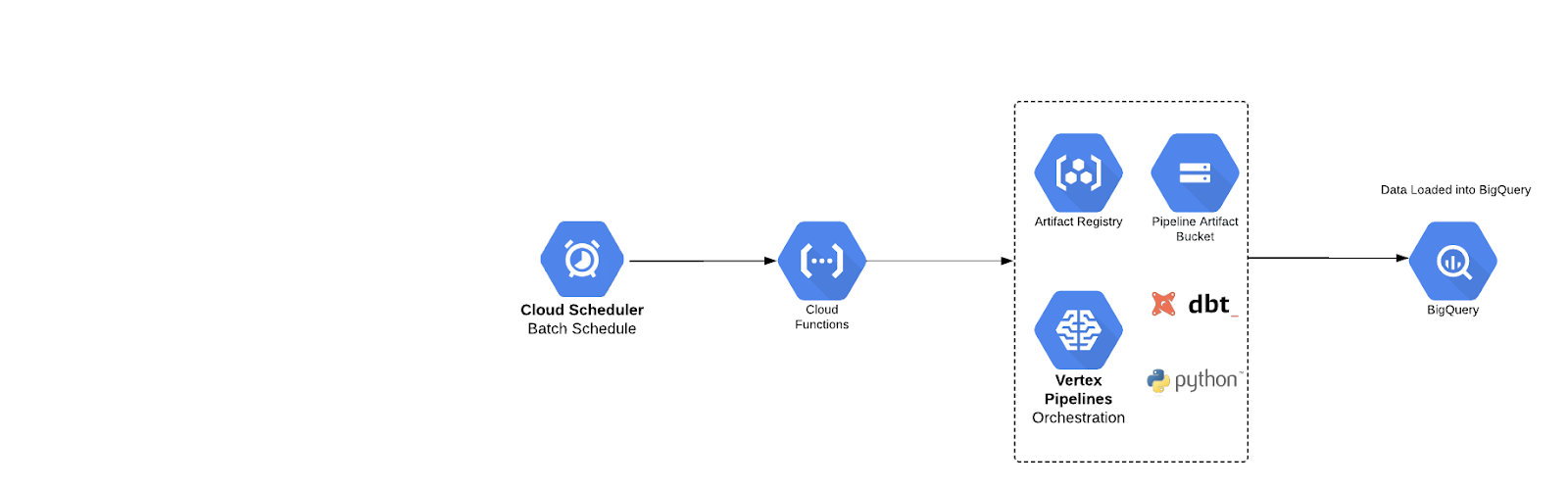
Here we’ve defined a simple pipeline, however, this general approach can be expanded to accommodate multiple different transformative steps in conjunction with ML oriented steps.
Conclusion
In general, running dbt on Vertex AI Pipelines can prove beneficial, cost-effective and a neat way to orchestrate dbt with pre-existing or future Machine Learning workloads. The examples given here are for simple dbt operations, but in reality, more complex pipelines can be implemented with multiple different dbt component spec files, more sophisticated service controls and network features. It will become increasingly interesting in the future to see what other integrations appear with Vertex AI and the results they achieve.
Want to know more about tools available on Google Cloud? For a deep dive into each key stage of the ML model lifecycle, the pros and cons of the available tools, such as Vertex AI, Cloud Composer, Dataflow, Cloud Run, and more, download our guide to MLOps Tools here.


