MLOps Tools Part 2: Kubeflow Pipelines vs. Cloud Composer for Orchestration

In part one of our MLOps Tools series, Aman compared TensorFlow Transform with BigQuery for data transformation. If you missed it, make sure you check it out here. In this part, we’ll be taking a deep-dive into orchestration tools on Google Cloud Platform (GCP): Kubeflow Pipelines vs. Cloud Composer.
Choosing the right orchestration tool is particularly important when evaluating the creation of an MLOps platform and will affect every step of the ML Journey that leads to model deployment:

Orchestras and Orchestration
When talking about IT systems and Cloud Architectures, the word orchestration refers to the automated configuration, coordination, and management of computer systems and software.
This word originates from Orchestra, which in classical music defines the study or practice of writing music for an orchestra.
I always found really accurate the usage of this word when talking about computing systems: if we think of our system as an orchestra, each one being a different instrument, the orchestrator would be for sure the conductor of the orchestra, fitting together all the different instruments in order to play the song.
Just as the conductor is a crucial part of the orchestra, the orchestrator plays a central role in any Cloud Architecture. Because of that, choosing the right orchestration tool in a Cloud Architecture or more specifically in a Cloud MLOps Architecture is really important as every orchestrator has different peculiarities and things that come out of the box.
During the last year, our MLOps team has developed a lot of experience in using the two main orchestrators available in GCP: Cloud Composer, built on the top of the open source framework Apache Airflow; and AI Platform Pipelines, based on Kubeflow Pipelines.
This blog summarises all of the insights we collected about these two products, in order to help you choose what orchestrator would fit better in your MLOps architecture.
Cloud Composer
Cloud Composer (see more here) is the GCP managed orchestration service built on top of Airflow. Airflow is an open source framework for orchestration of data engineering tasks, which centers around the concept of Directed Acyclic Graphs (DAGs). A DAG, similar to a flowchart, can be defined in Python to execute tasks with complex inter-dependencies between them.
On top of Airflow, Cloud Composer allows easier creation of the environment with no need to worry about the underlying infrastructure, good integration with other GCP tools, and robust monitoring through Cloud Operations monitoring and logging.

Reasons to use Cloud Composer for MLOps
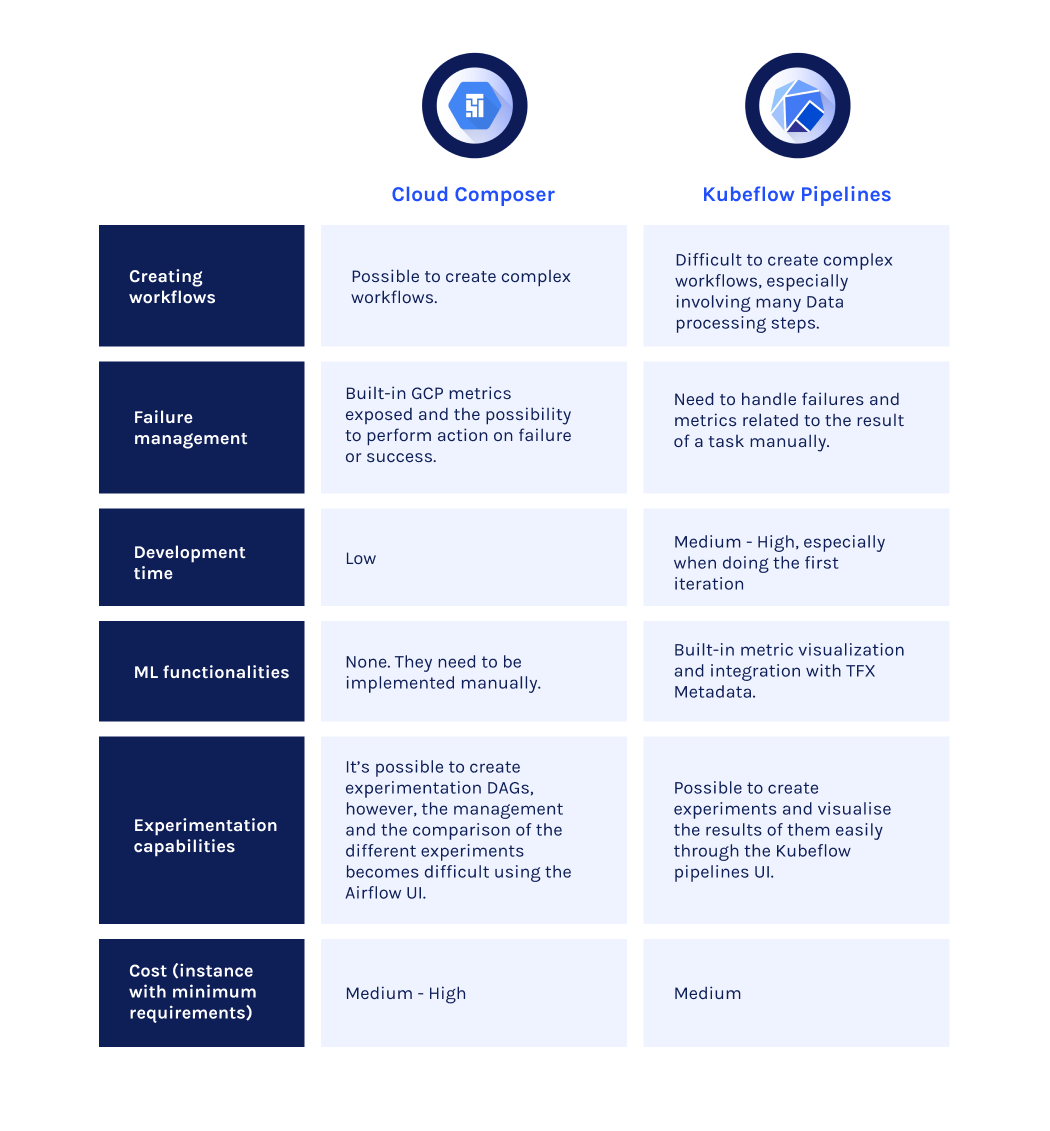
- Solve complex data processing problems: As said before, Airflow was originally built to solve data engineering problems but because of the flexibility it has, it can be used for any kind of orchestration. Airflow makes it easy to build a DAG with complex dependencies, something that may be required especially when orchestrating ingestion/preprocessing/feature engineering tasks. A DAG in Airflow can be defined directly as Python code. In addition to that Airflow provides strong templating capabilities through Jinja2 and Airflow macros. Implementing complex data processing workflows in Kubeflow Pipelines is possible but more complicated as the SDK, based on Argo, uses python to create a YAML file behind the scenes. This makes it complicated if not sometimes impossible to create specific dependencies between tasks such as branching a task or executing on condition. Furthermore, Kubeflow Pipelines has a really limited usage of macros and no built-in templating system.
- Failure management and monitoring: in a production environment it is really important to consider how to manage failures. This includes being notified when a failure occurs and recovering from it. Composer by default exports the result of every task and every DAG to Cloud Monitoring as a metric, allowing stakeholders to be notified when a failure occurs via email or other channels. Recovering from failures is facilitated in Airflow by a series of actions the user can take, like clearing a single task or performing backfill. AI Platform Pipelines doesn’t have this built-in capability; instead, you will need to use a Cloud Monitoring custom metric and handle any error or failure in a container manually.
- Easier to create workflows: in Composer, any workflow or task can be defined as simple python code. Because of that it is really easy to create a first DAG for someone starting with Airflow. AI Platform Pipelines is instead container-based. Every task requires the creation of a container with the configuration of the inputs and outputs of it. Executing every task in separate containers has some advantages, such as the capability to run heavy workloads in Kubernetes; and disadvantages, such as the increased complexity in creating and debugging the task. In AI Platform Pipelines building a container for every task is necessary as it is only possible to create python function-based tasks for really simple logic that doesn’t use any ML or GCP library. Composer allows you to create either function-based or container-based tasks.
We recently suggested Cloud Composer as orchestrator for a fraud detection MLOps platform involving complex ingestion and preprocessing tasks. We also plan to use Composer to orchestrate the insertion of features in the feature store.
AI Platform Pipelines (Kubeflow Pipelines)
AI Platform Pipelines (see more here) allows the creation in a couple of simple steps of a Kubernetes engine Cluster with Kubeflow Pipelines standalone installed on it. Kubeflow Pipelines is a container-native workflow engine based on Argo for orchestrating portable, scalable machine learning jobs on Kubernetes. Belonging to the Kubeflow ecosystem, it can be either installed by default with Kubeflow or as an alternative installed as standalone.

Reasons to use AI Platform Pipelines
- Orchestrator built for ML workflows: Kubeflow Pipelines is built specifically for data scientists and ML engineers to create ML workflows. The service has tight integration with TFX ML Metadata for metadata logging, support for metrics visualization output, and comparison between different runs. Cloud Composer requires the implementation of these ML capabilities as it is not originally built for ML workflows. Any interaction with the ML Metadata Database needs to be done manually. In addition to that, the visualization of the metrics for a run or the comparison between different runs needs to be done outside the Composer environment.
- Reduce the gap between experiment and production: Kubeflow Pipelines is highly oriented for experimentation. This is achieved primarily by the interface of the service itself, which allows you to collect and compare runs over experiments. In addition to that, GCP offers AI HUB, a repository dedicated to Kubeflow Pipelines workflows; and Notebooks, where it is possible to share a variety of plug and play reusable pipelines. In Cloud Composer experimenting with a new model or feature is also possible, for example, Data Scientists can create a new workflow to do that, changing the input parameters of it. However, this action in Composer is not supported by the interface of the service, which doesn’t help to visualise the result of a single run.
- Reduce cost: the monthly cost of a Google Kubernetes cluster for AI Platform Pipelines with minimum requirements is 40% cheaper than the monthly cost of a Composer Cluster with minimum requirements. We have a monthly cost of 218 USD for AI Platform Pipelines and a monthly cost of 368 for Composer.
- Serverless AI Platform Pipelines: in the last Next on Air, Google Cloud presented as a new product a managed and serverless version of AI Platform Pipelines, currently in alpha. It will allow any data scientist to run workflows on AI Platform paying only for what you use, with no need to create a Kubernetes cluster to orchestrate the job. In addition to that, any pipeline developed with AI Platform Pipelines can be ported to the managed version and vice versa.
We used Kubeflow Pipelines in a recent project to help Emotion AI pioneer, Realeyes, enhance their R&D capabilities with MLOps. Due to their big Data Scientists team and the fact that their core product is powered by Machine Learning, they are required to perform several experiments and iterations over a certain model whilst keeping MLOps best practices. Kubeflow Pipelines enabled them to do exactly this, making it a great tool of choice for their orchestration.
Summary
In this blog, we have seen how choosing the right orchestrator for an MLOps platform is a complex task, which needs to take into account the requirements of the platform itself.
Cloud Composer is particularly suggested in architectures requiring complex data pipelines for ML. This choice will enable data scientists and Machine Learning engineers to use Airflow’s capabilities to create complex DAGs, but also require manual implementation of ML functionalities such as metadata storage and metric visualization and evaluation.
When the architecture doesn’t involve complex data processing pipelines, or when Composer is not already used as orchestrator for other data transformations, AI Platform Pipelines is the suggested choice due to the built-in functionalities to orchestrate ML workflows, as well as the reduced monthly cost compared to Cloud Composer and the possibility to migrate the workflows to Serverless AI Platform Pipelines in the future.
We hope you enjoyed our MLOps tool comparison blog for Orchestration. To see our team’s evaluation on Run Cloud to Cloud Functions for Serving, check our part 3 of our series.
Want to know more about MLOps? Download our 2021 Guide to MLOps here.




