MLOps Tools Part 1: TensorFlow Transform vs. BigQuery for Data Transformation

Deploying a Machine Learning model in production can be challenging. So challenging, in fact, that 87% of data science projects don’t even make it to production. Problems that teams face include a lack of collaboration across teams; a lack of standardisation of processes; and a lack of visibility across the entire end-to-end workflow.
Over the last couple of years, a set of practices has emerged specifically to combat these issues. This is known as MLOps, which combines Machine Learning, DevOps, and Data Engineering practices to deploy and maintain ML systems reliably and efficiently.
This guide is the first of five in a series to help you choose the right tool for every step of your ML Journey to implement MLOps practices on Google Cloud Platform. Google Cloud Platform is an excellent environment for MLOps due to its presence of managed resources such as BigQuery, AI Platform and Cloud Run. This allows Data Scientists to focus more on the data and machine learning and not in solving infrastructure or operations problems. Each of our upcoming blogs will compare two tools for a crucial section of the ML Journey, highlighting some of the stages that are often overlooked.
- Part 1: Data Transformation – TensorFlow Transform vs. BigQuery
- Part 2: Orchestration – Kubeflow vs. Composer
- Part 3: Serving – Cloud Run vs. Cloud Functions
- Part 4: Monitoring – Cloud Monitoring vs. Grafana
- Part 5: Feature Store – BigQuery + Memorystore vs. FEAST
This blog will be covering Data Transformation, which involves changing the structure or format of the data to another so it is Machine Learning ready. More specifically we will be taking a look at Data Preprocessing and Feature Engineering on Google Cloud Platform, with a deep dive into two tools, BigQuery and Cloud Dataflow, more explicitly using TensorFlow Transform for preprocessing. In the image below, we have a diagram of the end-to-end Machine Learning workflow.
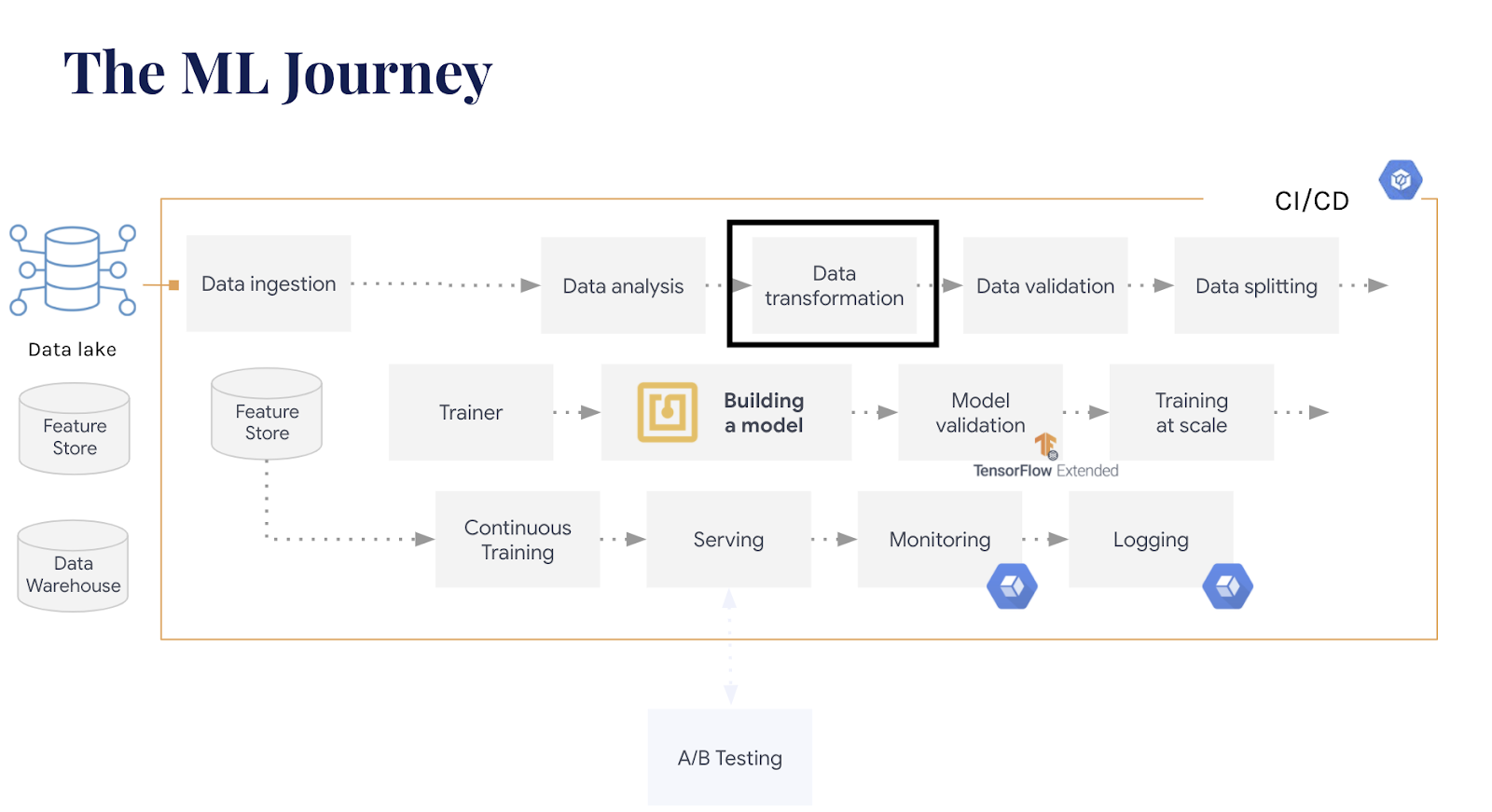
Data Preprocessing & Feature Engineering
Data Preprocessing is the process of transforming raw data into more meaningful data which can be understood by models. Raw data or real-world data is often riddled with errors, incomplete and inconsistent. To transform the raw data, we can apply multiple preprocessing steps that will help us train our models such as Normalization, Feature Construction and Data Cleansing.
Feature Engineering is the process of extracting and creating features from the raw dataset that will most impact the performance of the model. This is done by having in-depth knowledge of your raw data and the algorithm you will be using for training. By doing this, you remove the features that are not relevant and don’t contribute to your model performance, thus making your hypothesis space smaller, allowing your model to learn faster with ease. This step also includes the splitting of the data in training, test and validation for training.
Now that we know what both Data Preprocessing and Data Featuring is, let’s see what is the best way for you to complete these tasks on Google Cloud Platform. As mentioned above, we will be looking at two different tools; BigQuery, and Cloud Dataflow with the usage of TensorFlow Transform. To compare the following tools, we will mainly look at the three different types of preprocessing granularity explained below.
- Data point transformation: A straightforward transformation is applied to the data such as creating a boolean flag, multiplying two features together, adding a threshold to a feature, or scaling the feature. This type of transformation can be done for both training and prediction.
- Statistical data transformation: This type of transformation applies to the whole dataset and is used to analyse the data. Examples of transformations here are mean, median, quantiles, and standard deviation. This transformation should only be done in training to avoid feature leakage.
- Window aggregations: This method consists of creating a feature by aggregating or summarising the features over a period of time. For example, if you wanted the number of customers who bought a particular product in the last 24 hours or 48 hours.
BigQuery
BigQuery (see more here) is a scalable, serverless and fully-managed data warehouse, developed by Google Cloud, which allows you to perform super-fast SQL queries over petabytes of data. It is offered as a Platform as a Service (PaaS) and is built upon Google infrastructure. It also has many other features such as apply machine learning models to your data through SQL and to allow streaming inserts straight into your data warehouse.
Preprocessing Granularities
- Data point transformations: For simple Data point transformations, BigQuery works great; it is easy to implement, and the queries run extremely fast. BigQuery UI also provides a neat interface to write your scripts on, and there is adequate error checking functionality for your scripts.
- Statistical data transformation: There are many functions you can apply to your data such as
MIN,MAX,AVG, but it doesn’t cover everything. For some statistical analysis, you may be able to solve it by creating custom User Defined Functions, but that comes at the cost of implementing your logic and ensuring that it is correct and works the way you want it to.
- Window aggregations: It is possible to do transformations over a period of time, for example, the last n seconds, hours or days. BigQuery executes these queries very quickly, however depending on the size of your data splits, e.g. size of your window, you may run into memory issues. There are ways around this, such as partitioning your window into smaller overlapping windows and unioning them all in the end.
Additional reasons to use BigQuery for Data Transformation
- Fully managed, based on SQL: Being able to use SQL is one of BigQuery’s most significant advantages for data transformation, allowing you to steer clear of programming languages such as Python and Java. You also do not need to worry about your infrastructure or any additional resources; you can direct all your attention towards the SQL scripts.
- Keep storage and processing in the same environment: BigQuery is a potent tool and has many functions. A significant advantage of using BigQuery for preprocessing is that you can use the same tool for storage of your data and preprocessing of your data. You can also save your queries in BIgQuery and share it amongst the users who have access to your project. This means that you only need to leave BigQuery for the model training and that’s only if you’re training outside BigQuery. BigQuery now also has ML capabilities allowing you to train your data on algorithms such as Linear Regression or clustering. This means from storage to preprocessing to training; you can use just one tool, BigQuery.
We recently chose BigQuery for a customer, who is an industry leader in payment processing, and we were tasked with showing them the benefits of Google Cloud Platform for their machine learning model development. We chose BigQuery for data transformation for multiple reasons. Firstly, the client required aggregated windows to track user activity over a period of time, and BigQuery handles this task with ease. Second, we wanted to utilise User Defined Functions so that we could do additional statistical data transformations. Third, we only wanted to use one tool for the whole transformation, including cleaning, all transformations and splitting of the data so we could have it ready for the machine learning model. Finally, we didn’t want to manage resources and have to keep track of them. With BigQuery being fully-managed, we were able to focus solely on the SQL code.
TensorFlow Transform with Cloud Dataflow
Cloud Dataflow (see more here) is a managed service with the Google Cloud Platform ecosystem to allow you to execute Apache Beam pipelines at scale. It provides the ability to process data in batches or real-time efficiently and also be cost-effective. It has multiple SDKs in which pipelines can be created, for example, the Python and Java SDK. Now even though we can perform preprocessing of data using Apache Beam, and have it managed with Cloud Dataflow, we will be talking about using the TensorFlow library, TensorFlow Transform (tf.Transform) within Dataflow.
Tf.Transform is a library specifically developed to preprocess data. There are two main outputs when the library is applied: the first is the training data, ready to be read by your machine learning model; the second is a graph consisting of all your logic applied to the training data, which can then be used to apply to your prediction data. This allows you to save time and not have to duplicate your preprocessing logic when it comes to predictions.
Preprocessing Granularities
- Data point transformations: tf.Transform has many built-in functions for this, such as
scale_by_max_min,scale_to_0_1andPCA. It even has some complicated, machine learning ready processes such ascompute_and_apply_vocabulary, which generates a vocabulary for a categorical feature and maps it to an integer; andtfidf, which maps the terms in x to their term frequency multiplied by the inverse document frequency.
- Statistical data transformation: Like BigQuery, there are many built-in functions you can use. The options are similar to what you get with BigQuery. You also have the option of creating your own functions through Python code, but this comes at a cost. As all computations for transformations are saved to a graph for serving, some custom functions may cause issues due to not being saved properly on the output graph. These errors can be quite tricky to debug, as well.
- Window aggregations: It is not yet possible to do this type of transformation with tf.Transform.
Additional reasons to use TensorFlow Transform for Data Transformation
- Better integration with TensorFlow Extended (TFX): If you are using TFX throughout your project, then it is recommended that you use tf.Transform as it will be better integrated into your project.
- Training-serving skew: As mentioned earlier, one of the outputs of the tf.Transform is a graph which represents all the calculations and transformations done to your training data. This graph can then be applied to your prediction data too, which ensures that there are no differences in the way your training and serving data has been transformed.
TensorFlow Transform was recently used for data transformation for a client for their MLOps solution. The client, a leader in the telecommunications industry, wanted to build a common framework for development to production of machine learning models. They used TFX end-to-end for their NLP use case to enforce best practice on production. Therefore TensorFlow Transform was used at this part of the process. TensorFlow Transform also allows you to avoid code duplication, given that the transformations you do during training are the same you are doing during prediction. As mentioned above, tf.Transform produces a graph which records all the calculations done and can be applied to the prediction data. This was done to avoid training skew.
Summary
There are many differences between the two tools and a lot of things you need to first ask yourself before making your choice. The most significant advantage of choosing BigQuery over tf.Transform is that BigQuery is serverless. On the other hand, with tf.Transform, which runs on Dataflow, you need to configure everything yourself such as the clusters, workers and RAM. For BigQuery all you need to worry about is the SQL code that you are writing, not about managing your python code and the library versions. On top of that, tf.Transform is still under development so that some functions may be a little buggy. If you want something reliable, then I would recommend you go with BigQuery. Finally, if you would like to do Window Aggregations, then BigQuery is a clear choice here as tf.Transform does not support it yet.
For extra reference on data transformation and preprocessing, you may also want to have a read of this fantastic article written by the folks over at Google.
We hope you enjoyed our first MLOps tool comparison blog and that it makes choosing the transformation tool for your task easier. Check out our next blog, comparing Kubeflow with Composer for orchestration!




