How to Efficiently Grow Your All-Around ML Capability, from R&D to Production!

The discipline around providing infrastructure and best practices in machine learning, MLOps, is starting to take shape and is reminiscent of the early days of DevOps. Its goals are to increase automation while maintaining quality, and to establish a shared set of best practices and communication guidelines between data scientists, machine learning engineers, machine learning researchers and operations engineers, to help manage the development and delivery of machine learning services. While there are multiple significant differences between software engineering and machine learning engineering, there are enough parallels to motivate a knowledge transfer between DevOps and MLOps.
To learn more about MLOps, what “good” MLOps looks like, and how to make your AI workloads faster, scalable, and more efficient, have a look at our 2021 Guide to MLOps.
This blog post will explore the current MLOps landscape, identify its constituent parts and point to some well-established best practices in each area. It is mainly aimed at practitioners of machine learning that are looking to organise their workflow around developing and deploying machine learning models. We will explore the literature on the topic, some open-source tools and various offerings available on Google Cloud Platform.
Let’s get started!
1. The ML Team

If you are a machine learning practitioner, the following scenario is probably familiar to you. You have a machine learning project or idea, you look at the relevant literature, and start developing models that are spread across jupyter notebooks, each relying on carefully crafted custom data loading pipelines; eventually, one of the models works well enough to be deployed, and you scramble to refactor your code and make it production-ready in time. There may be dedicated engineers in your team tasked with converting notebooks to production-ready code but the same pain points exist regardless.
Splitting the areas of concern across team members, where the ML Researcher develops the models and the ML Engineer refactors the code and makes it production-ready, is a viable way to scale up teams, but it comes with downsides – nobody understands the entire system from end to end anymore. So, what is the best way of managing this siloing effect?
In Google’s paper “Machine Learning: The High-Interest Credit Card of Technical Debt”, the authors explain how employing a cross-functional research approach where engineers and researchers are embedded together on the same teams has worked best at Google and has helped reduce this source of friction significantly.
On the other hand, a functional approach is still a viable alternative where a solution to reduce friction between ML Researchers and ML Engineers could be to have jupyter notebook templates that define common functionality (e.g. connecting to a database and fetching data or running jobs on ML engine), so that the gap between researching an idea and testing it is minimised.
In both scenarios, it is fundamental to follow a set of common best practices in machine learning, to define a well-structured MLOps process for the team.
2. MLOps
Implementing a good code development and review practice, and using a proven workflow within your preferred version control system is an essential step in successfully delivering a machine learning solution. Additionally, there are tools available for continuous integration and testing, packaging and containerisation, release automation, infrastructure configuration and management and monitoring that can automate most of the process.
These are all problems successfully tackled by DevOps and applicable to the MLOps space. The DevOps landscape has already been explored in detail in countless blog posts and articles (for a quick overview, there is a great periodic table of DevOps tools on this page). On the other hand, delivering machine learning services comes with a new set of concerns including reproducibility of models and predictions, diagnostics, testing of models, management of data and model versions, interpretability and continuous improvement and re-training of models.
There are great open-source tools allowing you to structure your machine learning lifecycle in a traceable and reproducible fashion. A great example is MLflow. MLflow is a new open-source platform to manage the ML lifecycle, including experimentation, reproducibility and deployment. It includes a way to record and query experiments – code, data, config, and results. It also comes with a packaging format for reproducible runs on any platform and a general format for sending models to diverse deployment tools. If you want to learn more, have a look at this tutorial.
If you are after a database with data versioning capabilities built in, you might want to look into OrpheusDB. OrpheusDB is built on standard relational databases and offers similar benefits to them but also efficiently stores, keeps track of and recreates data versions on demand. This blog post goes into more detail on why OrpheusDB might be a solution to your data versioning needs.
Another framework in the open-source software ecosystem is Seldon Core, which is a platform for deploying machine learning models on Kubernetes. It supports any machine learning toolkit or programming language, provides easy integration (via REST or gRPC), provides runtime inference graphs (enables complex runtime inference graphs composed of models, routers, combiners and transforms to be deployed as microservices) and full lifecycle management (updating, scaling, monitoring and security). It supports deployment of machine learning models in the cloud (supports both AWS and GCP) or on-premise, obtaining metrics to ensure proper governance and compliance for your machine learning models and provides a consistent serving layer for models built using various ML toolkits and frameworks. To learn more about how to get started with Seldon Core, please refer to the documentation. Seldon also has an enterprise solution that unlocks the power of large-scale machine learning.
Hereafter, we’ll focus on MLOps in the cloud, namely Google Cloud, as the best solution for highly scalable, reliable, fast deployment of machine learning solutions for the enterprise.
First off, I recommend reading Google’s Rules of Machine Learning: Best Practices for ML Engineering guide which is very informative and will set you on the right course in your machine learning engineering journey!
- End-to-end Machine Learning in the Cloud
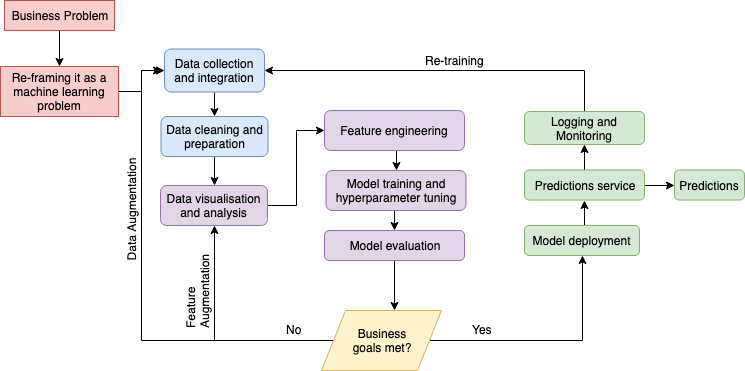
Cloud providers like Google Cloud have taken strides to offer managed solutions within machine learning and bridge the gap between R&D and production-ready machine learning services. Google Cloud Platform (GCP) has a multitude of services that can help along the journey from having a business problem to having a productionised machine learning model serving predictions, with the typical journey outlined in the diagram above.
While the business problem and machine learning problem definition are unique to each use case, the machine learning flow should follow a common, step-to-step strategy.
First step: data discovery, integration and analysis

At the data collection stage, Google Cloud Storage can be used to store raw data. Google Cloud Storage is a fast and simple object store with full integration with other GCP products. From there, Cloud Pub/Sub could be used to react to events (e.g. file drops), trigger data processing and store the processed data in Big Query for analysis. Cloud Pub/Sub is a scalable event ingestion and delivery system that supports the publish-subscribe pattern; Big Query is a fully managed data warehouse for analytics. Alternatively, if more complex data processing is needed or streaming data needs to be processed on the fly, Cloud Dataflow could be utilised. Cloud Dataflow is a fully managed service for transforming and enriching data in stream and batch modes. After the data is processed, Cloud Dataprep (data service that makes data visualisation, exploration and cleaning easy) can be used to explore the data and prepare it for analysis. There is also Cloud Datalab, an interactive tool built on Jupyter aimed to help with data exploration, analysis, transformation, visualisation and for building machine learning models on GCP (e.g. you can send out training jobs to Cloud ML Engine directly from the notebook). Additionally, TFX, an end-to-end platform for deploying production ML pipelines, native to Tensorflow can help you move your models from research to production. Last but not least, you could use tools such as Data Studio, Tableau or Looker to visualize your data for Business Intelligence.
Second step: Machine learning model design

The diagram above, borrowed from a 2018 Google presentation on how to solve business problems with machine learning, summarises the extensive offering for machine learning by GCP. If you want a hassle-free integration of ML into your service, Google Cloud AI offers multiple APIs that are plug-n-play and include Cloud AutoML (state-of-the-art transfer learning and neural architecture search technology), Cloud Video Intelligence API (video analysis, makes videos searchable and discoverable), Cloud Vision API (automatic image classification and segmentation) and Cloud Natural Language API (multi-language text analysis, reveals structure and meaning of text). If you want to deploy a custom model in a hassle-free way, Cloud Machine Learning Engine is a managed service that handles the provisioning of infrastructure that is needed for training and inference; it supports multiple frameworks (tensorflow, scikit-learn, XGBoost and Keras), hypertuning and portable models, with its offering continuously growing.
Final step: deployment
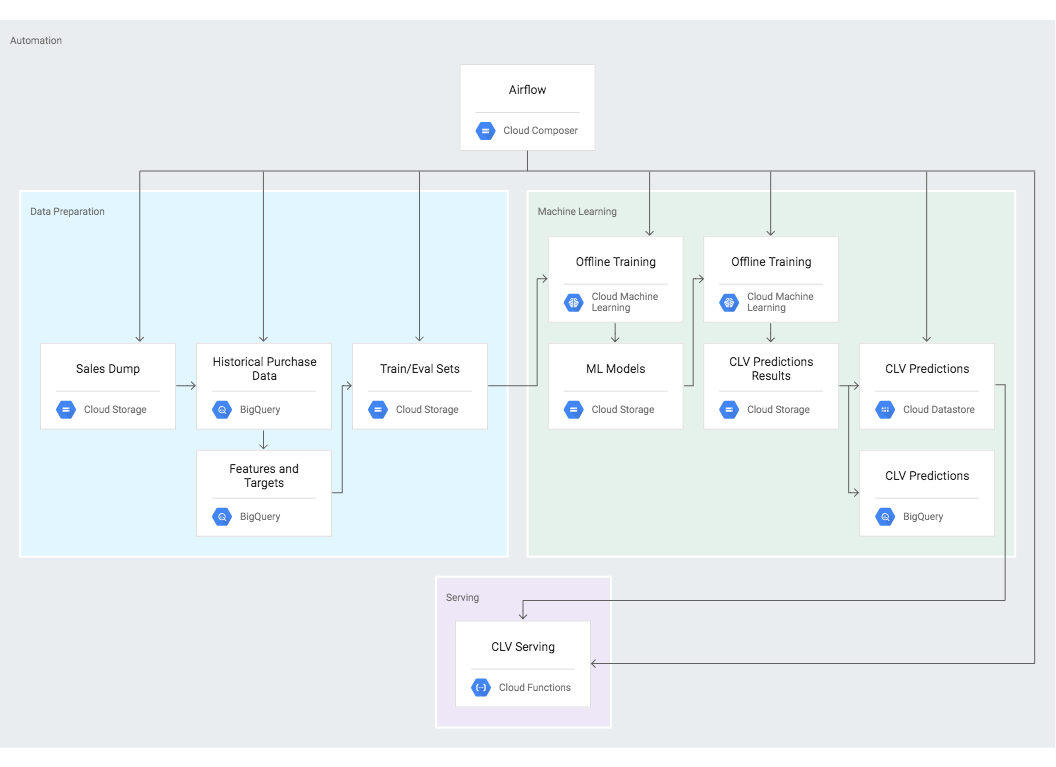
If full automation is required, Cloud Composer can help. Cloud Composer is a fully managed workflow orchestration service that is built on Apache Airflow; it allows you to run any GCP pipeline on a schedule. Else, if you are dealing with event-driven architecture, Cloud Function is the tool for you. Cloud Function is a serverless execution environment for building and connecting cloud services, via Python scripts. If no specific process is required to schedule or trigger your prediction/training pipeline, you could simply rely on Cloud Machine Learning Engine for serverless, cost-effective training and prediction. If you want complete control over your machine learning pipeline, Kubernetes Engine may be the best option for you to deploy and manage your machine learning infrastructure and jobs. If you are specifically using TensorFlow, Kubeflow might be best for you – its aim is to simplify the deployment of machine learning workflows on Kubernetes. There is also Argo for Kubernetes, a smart collection of tools to simplify Kubernetes workflow orchestration.
While the MLOps offering by GCP is extensive, it is highly dependent on the specific business requirements which tools work best for you. In our MLOps Tools Guide for GCP, we take a deep dive into each key stage of the ML model lifecycle, understanding the pros and cons of the available tools, such as Vertex AI, Cloud Composer, Dataflow, Cloud Run, and more, and detail how to make the right choice for you.
Want to get started with ML or improve your existing ML model’s performance? Request one of our AI Jumpstarts here!


