Responsible AI: Fairness Measurement + Bias Mitigation

Authors: Lily Nicholls, Senior Machine Learning Engineer and Matthew Gela, Senior Data Scientist
Bias and discrimination in Machine Learning
The majority of Machine Learning models have a direct impact on people’s lives and decision-making: product recommendations, forecasting churn, targeted ads, recruiting, estimating credit worthiness and aiding in criminal justice decisions are all examples of this. If these models are biased or discriminatory, they can have negative consequences for individuals and society as a whole.
As Machine Learning becomes increasingly integrated into various industries, there has been growing concern about the potential for biased algorithms to perpetuate and amplify existing social inequalities. In this blog post, we will explore the concept of fairness in Machine Learning, as well as the various methods used to measure, validate, and mitigate bias in ML models.
How to Define Fairness in Machine Learning Models
An important topic of conversation in the ML field is how to define fairness in the first place. There are many definitions of fairness (see 21 fairness definitions and their politics), which mostly conflict with one another. Equality of opportunity and equality of outcomes are two well-known fairness definitions that reflect very different realities.
This becomes more complicated when evaluating how a model performs on demographic subgroups of the data (e.g. gender, age, race etc.). Ideally, all ML models should perform fairly across all subgroups, but when there are so many definitions of “fairness”, how can we implement such standards in our Machine Learning models?
Firstly, we can look at the equality of common performance metrics across subgroups such as accuracy, precision or recall. Beyond that, we can think about a few more meaningful but concrete definitions of fairness:
- Demographic parity – the individuals across subgroups should have an equal proportion of positive outcomes (i.e. the sensitive feature is independent of the model’s prediction)
- True Positive parity and False Positive parity – the individuals across subgroups should have equal true positive or false positive rates
- Equalised odds – the individuals across subgroups should have equal true positive and false positive rates (i.e. predictions are correlated to a sensitive feature)
- Error rate parity – the individuals across subgroups should have equal error rates
Imagine a model that is used to diagnose a certain disease across a population, and it performs with a precision of 70%. When we split the data into adults and children, it’s clear there’s a stark difference in performance between the two subgroups. The image below shows that even though both subgroups have equal precision rates of 70%, the recall rate in children is 81% but only 56% for adults.

Source: https://pair.withgoogle.com/explorables/measuring-fairness/
We could aim to optimise the model towards an equal recall percentage across both adults and children, which would mean that both subgroups have equal rates of correctly identifying those who are actually sick. However, this would result in widening the disparity between precision rates (i.e. adults who have the disease are less likely to be diagnosed with it than children are).
Here you can see it is impossible to achieve equality of both of these metrics at the same time. While it may not be feasible to satisfy every fairness definition, you can prioritise the notions of fairness that align with your specific use case.
How to Measure Fairness
To measure fairness in a Machine Learning model, we need to first identify any protected or sensitive attributes the data may contain that might cause bias in the model’s predictions. Examples of such attributes are age, gender, race or disability. Once identified, select the fairness definition that best aligns with your use case.
An example where we may want to measure demographic parity is when hiring for a company, where you may want to have better representation across genders or ethnic backgrounds. However, demographic parity would perhaps not be an appropriate fairness definition to measure when looking at predicting the likelihood of patients developing a certain disease, as the disease may be more prevalent for certain demographic groups. Yet, if the model’s error rates were unequal across different demographic groups, it could lead to serious disparities in healthcare outcomes (e.g., people in a particular demographic could miss out on early interventions that would save their lives). In this case, a more appropriate fairness definition to measure would be error rate parity, which would look at the inequality in error rates across different demographic groups.
In order to measure the chosen definition of fairness, calculate the relevant metrics across the subgroups of the sensitive attribute. We can then compare and evaluate the performance metrics with the fairness metrics and set specific thresholds to identify if our model is biased towards any group in the sensitive attribute.
Still, it is not realistic to achieve exact equality across subgroups for any fairness definition. Therefore it’s important to decide on an acceptable range of difference (difference threshold) between the subgroups to determine whether a model is fair or biased. However, if the model exhibits significant unfairness, then the necessary actions have to be taken in order to mitigate this.
Mitigating Bias in ML Models
Bias can manifest itself in your Machine Learning datasets in many different ways. In a previous blog, we have discussed how this can happen, and how it can be perpetuated in Machine Learning models.
There are a few different stages where we can intervene to attempt to reduce bias:
Pre-Model Training
There are various steps data scientists can take to mitigate model bias, even before training the models. The first step would be to explore the data to identify bias or sensitive subgroups by looking at missing or underrepresented feature values (i.e. data integrity). For example, data points might only be collected at the point of a sale, disregarding data collection of unsuccessful sales. Developing an uplift model with this attribute would surely bias the model towards positive outcomes.
It’s important to ensure that the data is diverse, exhaustive and representative of the real-world population. If the data is skewed, this can introduce bias into the model.
For example, if a company has historically employed more men than women, a model that scores candidates for hiring could misrepresent the potential of female candidates. To correct the bias in misrepresented data, it is possible to augment the data to ensure that underrepresented groups are well-represented.
Entirely removing a sensitive feature from the data before a model is trained is another approach. This may be mandatory in some circumstances, such as if certain data features are prohibited by law to be included in the model training process. However, this won’t always be sufficient to solve the problem of bias. Other features (or combinations of them) could effectively act as proxies for the excluded, sensitive features. For example, due to various sociological circumstances, an individual’s race could be inferred from their postcode.
Model Training
Bias correction can be implemented using a fairness constraint during the model training process. A constraint defines the type of fairness you would like implemented on the sensitive feature during model training, such as demographic parity or equalised odds. For instance, a demographic parity constraint would ensure that outcomes are independent of the sensitive attributes, while an equalised odds constraint ensures that the model’s error rates are similar across all groups. These constraints modify the model’s objective function during training, adding a penalty term for fairness violations. In doing so, the model will not only learn to predict the target outcome accurately but also to satisfy the fairness criterion, creating a balance between predictive performance and fairness.
We will show you how you can implement a fairness constraint in the technical walkthrough.
Post-Model Training
Further options for mitigating bias can take place after the model is trained, by adjusting the model’s classification threshold for each subgroup. In this case, the threshold is adjusted to determine the sweet spot that minimises the disparity for a given fairness metric. This can be used when there is evidence that the model’s performance is biased across the demographic groups.
Consider a justice system challenge about predicting whether defendants are likely to reoffend i.e. being classified as either high-risk or low-risk. If we have a case where the model is predicting disproportionately higher risk scores for a particular ethnic group, and this is corresponding with a high false positive rate for this group, we could reduce the proportion of false positives by raising the threshold at which the defendant is deemed to be high-risk for that ethnic group.
Note that this doesn’t address the root cause of the problem. Also, adjusting the threshold by racial group is a controversial method for achieving fairness, since this could mean that two individuals, with the same predicted likelihood of reoffending who are from differing racial groups, would receive different treatment.
In production
Checking for bias isn’t something you can do just once and then forget about. Ensuring your model is fair demands ongoing attention when your model is up and running in a production environment. It is therefore important to continuously monitor fairness metrics for your models in production, and check for data drift for sensitive subgroups.
Technical Walkthrough
For this walkthrough, our goal is to identify any kind of bias towards sensitive attributes, and then mitigate that bias during model training. We are using a publicly available loan default dataset to train a model that will predict whether an individual will default on their loan.
Through some quick exploratory data analysis, we can see that the female subgroup has a lower loan default rate compared to the male and joint accounts subgroups (roughly 11% compared to 16%-17%).

How does this translate into the model’s predicted default rates? In order to measure fairness as part of our Machine Learning pipeline, we used the Fairlearn library. The Fairlearn library is an open source project that allows developers to improve the fairness of Machine Learning models.
We first initialise a dictionary that will contain the fairness metric(s) we want to calculate.

Afterwards, we define a MetricFrame object imported from the Fairlearn library. We pass the dictionary above, along with the ground truth labels, the predictions and the sensitive attribute(s) that we want to measure for fairness. Then we iterate through the MetricFrame object to add the results from all the measurements into a new dictionary for easier access. The MetricFrame object also enables us to calculate the metric differences between the subgroups which gives us insight into where disparity can exist.

The created dictionary is not only used for validation but also to create visuals to find out if there is any bias between the groups of the sensitive attribute. Creating these visuals makes it easier to identify any bias that exists.
From the graph below, we can see that there is some disparity in the predicted default rates between genders. Females have a lower selection rate i.e. a lower percentage of loans predicted as defaulting. This is between 3-7% lower than the other groups.

In the next part, we will assume that we want to mitigate this disparity in the predicted default rates across the gender subgroups and show you how to do this.
Bias mitigation
While mitigating bias pre- and post-model training is of major importance, we’re going to focus on the less covered aspect of mitigating bias, which is how you can implement it during the model training process.
The Fairlearn library has a selection of available fairness constraints and a reductions method which attempts to optimise a binary classification or regression problem subject to this constraint. In this example, we are interested in optimising for demographic parity, to ensure that model predictions are independent of gender.
It works by defining the fairness constraint and then wrapping the base algorithm with a reduction algorithm. Here we select a DemographicParity() constraint and wrap the XGBoost model with the ExponentiatedGradient() algorithm from the Fairlearn library. When this algorithm applies the .fit() method, it is able to return a fairer classifier under the specified fairness constraints. Note that in the code we have specified a difference bound of 0.01 which means the Exponentiated Gradient algorithm will attempt to optimise the model subject to a 1% disparity constraint in the selection rate between the subgroups. See the code snippet below which trains two XGBoost models, one with and one without fairness mitigation applied.

The graph below shows the performance of both original and mitigated models split by gender, looking specifically at the selection rate. Since demographic parity has been applied, the selection rates for the mitigated model are much more equal.
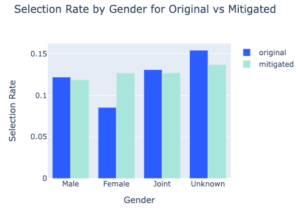
While we have demonstrated one technical approach to mitigating disparities for a particular fairness metric and sensitive attribute above, we do not recommend that you simply rely on this method to achieve a fair ML system. Ensuring your Machine Learning models are fair is much more complex and requires actions across the Machine Learning lifecycle to identify causes and assign appropriate mitigating actions.
Conclusion
Just like in the real world, bias within Machine Learning is prominent and should be identified and mitigated in order to treat individuals fairly and prevent our historical biases and prejudices from being fed into algorithms. In this blog, we have covered steps that can be incorporated into the Machine Learning process to first identify and measure fairness, and then to mitigate bias before, during and after model training.
Datatonic is Google Cloud’s Machine Learning Partner of the Year with a wealth of experience developing and deploying impactful Machine Learning models and MLOps Platform builds. Need help developing an ML model, or deploying your Machine Learning models fast?
Have a look at our MLOps 101 webinar, where our experts talk you through how to get started with Machine Learning at scale or get in touch to discuss your ML or MLOps requirements!


